TriBench
Reproducible Benchmarking for Triton Kernels
What is Triton?

Why Benchmark?
Comparability & Reproducibility
Kernel timings shift with JIT, warmup count, reps, and cache state — these settings must stay fixed across repos.
Maintainability & Extensibility
New kernels, shapes, dtypes, and backends drop in without one-off scripts. The workflow stays readable as the collection grows.
Diagnostic Value
Latency alone won't tell you where the bottleneck is. TFLOPS and GB/s show whether a kernel is compute- or memory-bound.
Measurement sensitivity
❌ Include JIT in timing
⚠️ No warmup
⚠️ Single execution
✅ Warmup + rep + quantiles
← lower variance is better
Goals
The Problem
Triton lets you write GPU kernels, but every repo ships its own
benchmark.py. Warmup, timing, and reporting all differ — results don't line up.
Turning collected kernels into a real suite requires one harness for correctness, fair timing, and readable metrics.
TriBench's Role
TriBench handles the Formalize and Aggregate steps:
- One
meta.jsonschema per kernel - Correctness gate before timing
- Standard warmup / rep / quantiles
- Derived metrics: TFLOPS, GB/s
- JSON + Markdown results with env snapshot
→ Turns a loose community kernel into a reproducible benchmark entry.
Landscape
| Project | Layer | Approach | Self-contained kernels | Data-driven config |
|---|---|---|---|---|
| Triton testing | Library | do_bench / perf_report — utilities, not a suite |
— | — |
| TritonBench | Suite | PyTorch op suite via submodules; broad coverage, monolithic setup | No | No |
| KernelBench | Eval | LLM evaluation: fast_p = correctness + speedup threshold |
Partial | No |
| MultiKernelBench | Eval | Multi-platform backend abstraction across DSLs | No | No |
| TriBench | Harness | Kernel packs + meta schema + CLI + result logging | ✓ Yes | ✓ Yes |
vs. Triton testing
Timing utilities only — no registry, no correctness checks, no saved results.
vs. TritonBench
One monolithic suite vs. self-contained kernel packs with local meta.json.
vs. KernelBench
TriBench can act as the execution layer underneath these generative benchmarks.
Core Design
📦 Self-Contained
Each kernel dir has meta.json + reference.py +
triton_impl.py. Adding a kernel = adding a folder.
🔌 Lazy Import
Kernels load on demand. One broken pack won't block the rest.
⚖️ Fair Timing
Compile and warmup happen outside the measurement window, so A/B comparisons stay fair.
🔮 Backend Support
The schema leaves room for other backends like ROCm/HIP.
Directory & Dependency Map
tribench/ ← Core engine
registry.py discover & lazy-load
meta.py parse meta.json schema
gen.py generate typed inputs
correctness.py validate vs reference
bench.py warmup → timing loop
metrics.py derive TFLOPS / GB/s
env.py snapshot environment
io.py save JSON + Markdown
cli.py CLI (validate/test/run)
kernels/<op>/ ← Kernel packs
meta.json entrypoints / cases /
dtypes / variants
reference.py PyTorch baseline
triton_impl.py Triton kernel(s)
bench_entry.py (optional) custom bench
The core only needs meta.json and an entrypoint
(file.py:symbol). A broken kernel stays isolated.
Pipeline
Why correctness first?
No point timing a wrong kernel. TriBench checks outputs and gradients against the PyTorch reference first.
What the timing loop does
Warmup first, then repeated timed runs. Reports min/max/mean
and p50/p95. Backends: do_bench, do_bench_cudagraph, raw
CUDA events.
What gets saved
- Latency quantiles (p50 / p95)
- TFLOPS and GB/s
- Environment: torch/triton/CUDA/GPU/driver
- Git commit hash + random seed
- Full CLI command line
→ JSON + Markdown outputs
Correctness Validation
PyTorch Reference Baseline
reference.py implements the same op in PyTorch as the ground truth.
Shape & Dtype Sweep
meta.json defines the test matrix. TriBench runs every listed size and
dtype (fp16, bf16, fp32).
Strict Tolerance Checking
Outputs and gradients are compared to the reference. max_diff must
stay within the dtype's tolerance.
Gate Before Benchmark
Only passing kernels move to timing. Broken ones never produce benchmark numbers.
Example: RMS Norm
$ tribench test --kernel rms_norm
Testing rms_norm...
fp32 (2048, 768) max_diff=1.2e-6 ✅
fp16 (2048, 768) max_diff=3.1e-4 ✅
bf16 (2048, 768) max_diff=4.7e-4 ✅
fp16 (4096, 1024) max_diff=2.8e-4 ✅
fp16 (8192, 4096) max_diff=3.5e-4 ✅
All 5 cases passed.Correctness first — so the numbers are worth trusting.
Timer Backends
do_bench
Default backend. Set warmup and reps; returns summary stats or quantiles.
do_bench_cudagraph
Uses CUDA Graphs to cut Python and launch overhead. Best for very short kernels.
CUDA Events
Direct GPU timestamps, manual warmup and sync. Use when you need full control.
Latency Distribution
Mean latency hides jitter and contention spikes. p50 = typical case, p95 = tail.
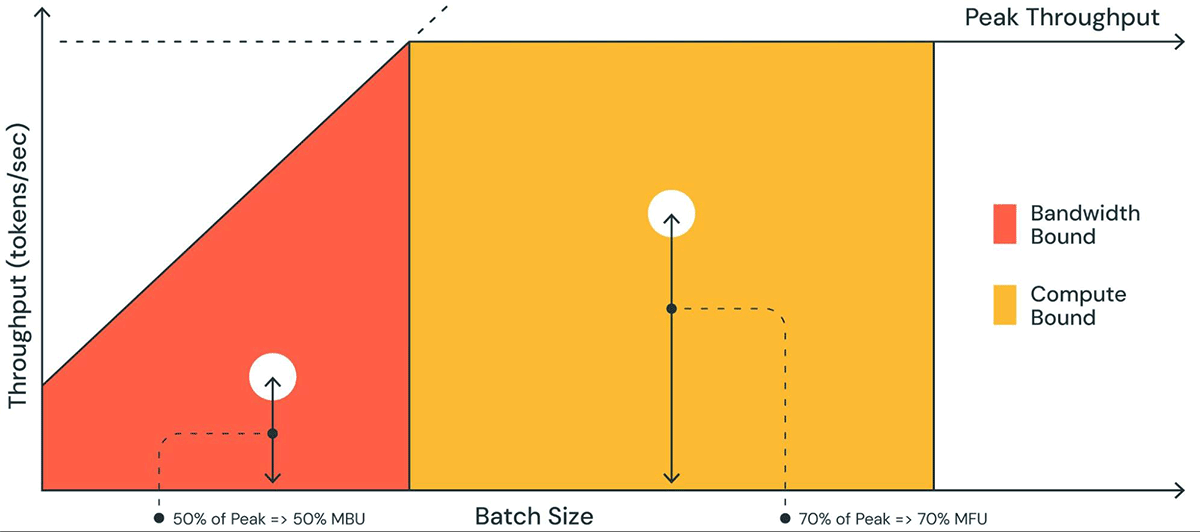
Throughput
📐 TFLOPS — Compute Throughput
TFLOPS measures how much compute the kernel actually uses — tells you if it's compute-bound.
e.g. 85 TFLOPS / 312 peak = 27% utilization
📊 GB/s — Memory Bandwidth
GB/s measures bandwidth usage — matters most for memory-bound ops.
e.g. 1200 GB/s / 2039 peak = 59% bandwidth
Reproducibility
🔒 Captured Per Run
Software Stack
torch / triton / CUDA versions
Hardware
GPU name, driver version, memory
Code State
Git commit hash to reproduce the run
Experiment Config
Random seed + full CLI command
📄 Dual Output Format
results.json
Machine-readable — for analysis, CI, and cross-run diffs.
summary.md
Markdown table for reports, READMEs, and submissions.
Self-Contained Results
Each result file includes the full environment snapshot — one JSON is enough to reproduce the run. Same schema across all 28 kernel packs.
Visualization
Composition
What variants means in
meta.json
A single kernel pack can hold multiple implementations. TriBench runs all of them with identical cases, dtypes, layouts, seeds, and timer settings.
Main Impl
Optimized Triton
Baseline
PyTorch reference
Ablation
Alt block sizes, etc.
Typical Use
Most kernels ship with a reference, an optimized
version, and a few experiments. variants keeps them in one place for easy
comparison.
⚡ Case: Add+SiLU Fused
Runs add + silu in one pass.
- 1 memory round-trip
- 1 kernel launch
- Minimal memory traffic
🔗 Case: Sequential Baseline
Runs torch.add then F.silu.
- 2 memory round-trips
- 2 kernel launches
- Higher memory traffic
Both live in one meta.json → comparison stays
consistent and repeatable
Developer Workflow
Validate Schema
Check that
meta.json is valid
tribench validate-metaTest Correctness
Compare shapes & dtypes to the reference
tribench test --kernel allRun Benchmark
Collect timing, metrics, and logs
tribench run --kernel rope --dtype fp16Get Started
Docs and quickstart guide
🚀 TriBench Getting StartedReferences
- Triton
github.com/triton-lang/triton - Liger-Kernel
github.com/linkedin/Liger-Kernel - FlagGems
github.com/FlagOpen/FlagGems - SageAttention
github.com/thu-ml/SageAttention - FlashAttention
github.com/Dao-AILab/flash-attention - FlashInfer
github.com/flashinfer-ai/flashinfer - TritonBench
github.com/meta-pytorch/tritonbench - KernelBench
github.com/ScalingIntelligence/KernelBench - MultiKernelBench
github.com/wzzll123/MultiKernelBench - NVBench
github.com/NVIDIA/nvbench - vLLM
github.com/vllm-project/vllm - SGLang
github.com/sgl-project/sglang - CUDA-Agent
github.com/BytedTsinghua-SIA/CUDA-Agent
Thank You
TriBench Team